| netlib.narod.ru | < Назад | Оглавление | Далее > |
Визуализация уровня как единой сетки очень проста, хотя и несколько неэффективна по времени. Но что делать в тех случаях, когда уровень требует большей детализации — зданий, деревьев, пещер и других необходимых для игры объектов? А как насчет того, чтобы немного упростить разработку уровней? Разве не было бы здорово рисовать уровни в программе трехмерного моделирования, такой как 3D Studio Max (также известной как 3DS Max) или MilkShape 3D, а затем помещать их в вашу игру?
Проблемы с большими детализированными уровнями возникают из-за количества полигонов с которыми приходится иметь дело. Рисование всех полигонов в каждом кадре неэффективно. Для увеличения скорости вы можете визуализировать только те полигоны, которые находятся в поле зрения, а чтобы игра работала еще быстрее, исключить сканирование каждого полигона сцены, определяющее видим ли он.
Как можно определить, какие полигоны видимы, не сканируя их все в каждом кадре? Решение заключается в разделении трехмерной модели (представляющей уровень) на небольшие фрагменты (называемые узлами, nodes), содержащие несколько полигонов. Затем вы упорядочиваете узлы в специальную структуру (дерево, tree) которую можно быстро просканировать для определения того, какие узлы видимы. Потом вы визуализируете видимые узлы.
Вы можете определить, какие узлы видимы, используя пирамиду видимого пространства. Теперь вместо того, чтобы сканировать тысячи полигонов, вы сканируете небольшой набор узлов, чтобы определить, что рисовать. Видите, насколько просто это улучшение процесса рисования?
Вижу, вы начинаете беспокоиться о том, как осуществить столь выдающийся подвиг. Позвольте представить вам движок NodeTree. Созданный специально для этой книги, он может взять любую сетку и разделить ее на узлы, используемые для быстрой визуализации сеток (например сеток, используемых в качестве уровней вашей игры).
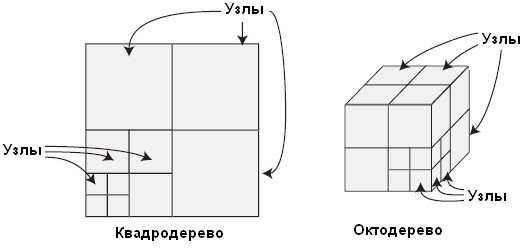
Движок NodeTree достаточно универсален, поскольку может работать в двух различных режимах (отличающихся способом разделения на узлы): режиме квадродерева (quadtree) и режиме октодерева (octree). В режиме квадродерева мир (и последующие узлы) делится на четыре узла. Этот режим лучше подходит для сеток уровней, где нет значительных изменений по оси Y (высота точки просмотра меняется не сильно).
Режим октодерева разделяет мир (и последующие узлы) на восемь узлов. Используйте этот режим для больших трехмерных сеток, в которых точка просмотра может располагаться в любом месте. Процесс деления продемонстрирован на рис. 8.4.
Рис. 8.4. Режим квадродерева разделяет мир (и последующие узлы) на четыре узла за раз, а режим октодерева разделяет мир (и последующие узлы) на восемь узлов за раз
Мир (представляемый как куб, заключающий в себе все полигоны, описывающие уровень) разделяется на меньшие узлы равного размера. Квадродерево разделяет узлы в двухмерном пространстве (используя оси X и Z), а октодерево разделяет узлы в трехмерном пространстве (используя все оси).
Я вернусь к разделению узлов чуть позже, а перед тем, как продолжить, хочу прояснить несколько моментов. Узел представляет группу полигонов и в то же время представляет область трехмерного пространства. Каждый узел связан с другими отношениями родитель-потомок. Это означает, что узел может содержать другие узлы, и каждый последующий узел является частью, меньшей чем его родитель. Весь трехмерный мир в целом считают корневым узлом (root node) — самым верхним узлом, с которым связаны все другие узлы.
Вот трюк для узлов и деревьев: зная, какие полигоны содержатся в узле трехмерного пространства, вы можете сгруппировать их; затем, начав с корневого узла, вы сможете быстро перебрать каждый узел дерева.
Чтобы создать узлы и построить древовидную структуру вы проверяете каждый полигон сетки. Не беспокойтесь; это делается только один раз и влияние этого процесса на быстродействие можно не учитывать. Ваша цель — решить, как упорядочивать узлы в дереве.
Каждый полигон сетки заключается в прямоугольник (называемый ограничивающим прямоугольником, как показано на рис. 8.5). Прямоугольник определяет протяженность полигона по всем направлениям. Если ограничивающий прямоугольник полигона находится в узле трехмерного пространства (полностью или частично), значит полигон относится к узлу. Полигон может относиться к нескольким узлам, поскольку протяженность полигона может распространяться на несколько узлов.
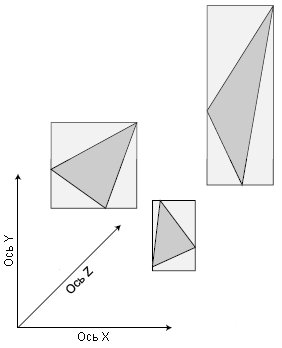
Рис. 8.5. У полигонов есть воображаемые (ограничивающие) прямоугольники, окружающие их. Ограничивающие прямоугольники полезны для быстрого определения местоположения полигона в трехмерном пространстве
В процессе группировки полигонов в узлы обращайте внимание, есть ли большие пространства между полигонами или много полигонов сосредоточено в одном месте. В последнем случае необходимо разделить узел на более мелкие подузлы и заново просканировать список полигонов, приняв во внимание новые узлы. Продолжайте этот процесс, пока все полигоны не будут разделены на достаточно маленькие группы и пока каждый узел, содержащий полигоны, не станет достаточно маленьким.
На рис. 8.6 показано несколько полигонов и мир (корневой узел), заключенный в квадрат. Квадрат разделен на меньшие узлы, а те, в свою очередь, также разделены на узлы. Каждый узел либо используется (содержит полигон или полигоны), либо не используется (не содержит полигонов).
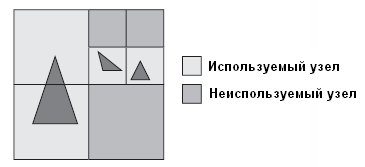
Рис. 8.6. Пример мира с несколькими полигонами, сгруппированными в узлы
Поскольку полигоны на рис. 8.6 расположены далеко друг от друга, вы можете разделить корневой узел на четыре меньших узла (создав квадродерево). Затем проверьте каждый узел и продолжайте разделять большие. Для ускорения процесса можете пропустить пустые узлы. В конце концов вы получите замечательную древовидную структуру, готовую для сканирования.
Построив древовидную структуру вы готовы визуализировать ее. Начав с корневого узла, вы выполняете проверку попадания узла в пирамиду видимого пространства. Узел считается видимым, если хотя бы одна из восьми точек (думайте о них, как об углах куба), формирующих его в трехмерном пространстве, находится внутри пирамиды видимого пространства или сама пирамида видимого пространства находится внутри узла.
После того, как вы решили, что узел видим, выполните ту же самую проверку для его дочерних узлов (если они есть). Если у узла нет потомков, проверьте, есть ли в нем полигоны, которые надо рисовать (дочерние узлы в процессе сканирования могут рисовать одни и те же полигоны). После того, как полигоны в узле нарисованы, они отмечаются, как нарисованные, и сканирование возвращается к родительскому узлу (и любым другим оставшимся узлам, которые будут просканированы).
Видите магию этого процесса: высокоуровневые узлы отбрасываются вместе с их потомками. Этот способ позволяет удалить из процесса визуализации тысячи полигонов и сэкономить время.
Когда вы будете работать с древовидными структурами и Direct3D, то обнаружите, что сетки содержат много материалов. Помните, что переключение материала это ресурсоемкая и медленная операция (особенно, когда каждый материал использует свою текстуру), так что здесь следует вести себя осмотрительно. Как можно нарисовать все видимые полигоны не переключая материалы снова и снова (даже возвращаясь к уже использованным материалам)? Здесь в игру вступают группы материалов.
Группа материалов (material group) — это набор полигонов, объединенных вместе на основании назначенных материалов. Поскольку сетка может содержать много материалов, имеет смысл визуализировать только те группы полигонов, которым назначен материал, установленный в данное время. В этом случае вы устанавливаете каждый материал (и соответствующую текстуру, если она существует) только один раз, визуализируете полигоны, использующие этот материал, и переходите к следующему материалу.
Хотя использование групп материалов выглядит логичным, группировка полигонов по их материалам усложняет работу со структурой NodeTree. Вы не можете знать, какие полигоны будут нарисованы не просканировав древовидную структуру. Необходимо просканировать дерево и построить список визуализируемых полигонов. Завершив сканирование просто проверьте список полигонов, относящихся к каждому из материалов, и работайте с ним.
Группировка материалов оказывает влияние только на порядок, в котором рисуются видимые полигоны. Симпатично, да?
Пришло время для программирования. Начнем с создания нескольких структур, представляющих вершины, полигоны, узлы и группы материалов:
// sVertex - это структура настраиваемого формата вершин,
// содержащая только трехмерные координаты. Она используется
// для получения информации о координатах из буфера вершин сетки
typedef struct sVertex {
float x, y, z; // Трехмерные координаты
} sVertex;
// Структура данных полигона хранит группу материалов (ее номер),
// номер кадра, в котором полигон рисовался последний раз
// (чтобы в одном кадре не перерисовывать его несколько раз)
// и три вершины, используемые для визуализации полигона
// (о которой вы прочтете позже)
typedef struct sPolygon {
unsigned long Group; // Группа материалов
unsigned long Timer; // Кадр последнего рисования
unsigned short Vertex0; // Индекс вершины 1
unsigned short Vertex1; // Индекс вершины 2
unsigned short Vertex2; // Индекс вершины 3
sPolygon() { Group = Timer = 0; }
} sPolygon;
// Структура данных узла хранит счетчик количества полигонов в узле,
// массив структур sPolygon, трехмерные координаты узла
// (а также размер от центра до ребра, поскольку наши узлы будут
// идеальными кубами) и указатель на дочерние узлы
typedef struct sNode {
float XPos, YPos, ZPos; // Координаты центра узла
float Size; // Размер узла
unsigned long NumPolygons; // Количество полигонов в узле
unsigned long *PolygonList; // Список полигонов
sNode *Nodes[8]; // Дочерние узлы 4 для квадродерева,
// 8 для октодерева
// Конструктор, используемый для очистки переменных
sNode()
{
XPos = YPos = ZPos = Size = 0.0f; // Местоположение и размер
NumPolygons = 0; // Полигонов в узле нет
PolygonList = NULL; // Очистка списка полигонов
for(short i = 0; i < 8; i++) // Квадродерево использует
// только первые 4
Nodes[i] = NULL; // Очищаем указатели
// на дочерние узлы
}
// Деструктор для очистки дочерних узлов и переменных
~sNode()
{
delete [] PolygonList; // Удаляем список полигонов
PolygonList = NULL;
for(short i = 0; i < 8; i++) {
delete Nodes[i]; // Удаляем дочерние узлы
Nodes[i] = NULL;
}
}
} sNode;
// Структура данных группы материалов используется как
// буфер индексов для хранения полигонов, которые необходимо
// визуализировать в одном кадре, а также содержит количество полигонов
// в группе материалов и как много полигонов рисуется в каждом кадре
typedef struct sGroup {
unsigned long NumPolygons; // Количество полигонов в группе
unsigned long NumPolygonsToDraw; // Количество рисуемых полигонов
IDirect3DIndexBuffer9 *IndexBuffer;
unsigned short *IndexPtr;
// Очистка количества полигонов
sGroup() { NumPolygons = 0; IndexBuffer = NULL; }
// Освобождение буфера индексов
~sGroup()
{
if(IndexBuffer != NULL)
IndexBuffer->Release();
IndexBuffer = NULL;
}
} sGroup;
Каждая структура хранит различные виды информации о сетке или структуре NodeTree. Базовой структурой данных настраиваемого формата вершин является sVertex; она напрямую отображается на все другие структуры данных вершин. Если вы загружаете сетку с диска, то должны использовать структуру sVertex для получения координат вершин.
Структура sPolygon используется для хранения информации о каждом полигоне сцены. Структура хранит номер группы материалов (материалы нумеруются от нуля до количества материалов минус один), номер кадра в котором последний раз выполнялось рисование (для предотвращения перерисовок) и три вершины, используемые для рисования полигона.
Структура sNode хранит количество полигонов, находящихся в узле трехмерного пространства. У каждого узла есть координаты, определяющие местоположение его центра, а также переменная размера, сообщающая расстояние от центра узла до одной из его граней (все узлы — идеальные кубы). Массив PolygonList вы используете для хранения индексов массива структур sPolygon (который содержит информацию о каждом полигоне в NodeTree). Также присутствуют восемь указателей на дочерние узлы, применяемые для формирования древовидной структуры. Обратите внимание, что квадродерево использует только четыре первых указателя на дочерние узлы.
Последняя структура, sGroup, управляет группами материалов. Вот здесь можно запутаться, главным образом потому, что я забыл познакомить вас в главе 2 с объектом IDirect3DIndexBuffer9. При создании NodeTree вам потребуется столько структур sGroup, сколько материалов находится в исходной сетке вашего дерева.
Каждая структура sGroup содержит информацию об отдельной группе материалов, такую как количество полигонов, использующих данный материал и количество рисуемых в кадре полигонов, которые используют данный материал. После построения списка рисуемых полигонов вам понадобится построить список буферов вершин, используемых для визуализации полигонов. Здесь-то и появляется объект IDirect3DIndexBuffer9.
В Direct3D есть два способа рисования полигонов — с использованием только буфера вершин и с использованием комбинации буфера вершин и буфера индексов. Вы уже читали о буфере вершин в главе 2; он работает путем назначения трехмерных координат вершин и их преобразования в полигоны на экране. Но что, если вы хотите использовать одну и ту же вершину снова и снова для рисования нескольких полигонов не тратя время и память на многократное сохранение данных одной вершины?
Здесь вам поможет буфер индексов. Помните, как в главе 2 создавая вершины мы нумеровали их? Эти номера называются индексы вершин (vertex indices). Так что вместо того, чтобы рисовать полигон задавая набор координат вершин, можно указать индексы вершин.
Например, установив буфер вершин, содержащий четыре вершины, можно создать буфер индексов для рисования двух полигонов, указав в нем, что первый полигон использует вершины 0, 1 и 2, а второй использует вершины 1, 2 и 3. Как видите, у нас по-прежнему есть буфер вершин, хранящий их координаты. Но, благодаря использованию буфера индексов, я могу использовать вершины 1 и 2 несколько раз. Это означает, что мне достаточно определить только четыре вершины, а не шесть (как было бы если бы использовался только буфер вершин).
Сам буфер индексов используется для хранения индексов вершин для рисования каждого кадра; поскольку все узлы сканируются в ходе визуализации, все видимые полигоны добавляются в список полигонов в различных группах материалов. Как только все узлы просканированы, каждая группа материалов рисуется с использованием ее буфера индексов.
Хватит говорить о структурах данных; пришло время перейти к коду класса. Взгляните на приведенный ниже класс, который берет сетку и преобразует ее в древовидную структуру по вашему выбору — либо в квадродерево, либо в октодерево:
// Перечисление типов древовидной структуры
enum TreeTypes { QUADTREE = 0, OCTREE };
class cNodeTreeMesh
{
private:
// Здесь помещаются показанные ранее объявления
// структур sVertex, sPolygon, sNode и sGroup
int m_TreeType; // Тип дерева
// QUADTREE или OCTREE
cGraphics *m_Graphics; // Родительский объект cGraphics
cFrustum *m_Frustum; // Пирамида видимого пространства
float m_Size; // Размер мирового куба
float m_MaxSize; // Максимальный размер узла
sNode *m_ParentNode; // Родитель связанного списка узлов
unsigned long m_NumGroups; // Количество групп материалов
sGroup *m_Groups; // Группы материалов
unsigned long m_MaxPolygons; // Максимальное количество
// полигонов в узле
unsigned long m_NumPolygons; // Количество полигонов в сцене
sPolygon *m_Polygons; // Список полигонов
unsigned long m_Timer; // Таймер рисования
sMesh *m_Mesh; // Исходная сетка
char *m_VertexPtr; // Указатель на вершины сетки
unsigned long m_VertexFVF; // FVF вершин сетки
unsigned long m_VertexSize; // Размер вершины сетки
// SortNode группирует полигоны в узлы и в случае необходимости
// разделяет узел на несколько потомков
void SortNode(sNode *Node,
float XPos, float YPos, float ZPos,
float Size);
// AddNode добавляет узел в список рисуемых узлов
void AddNode(sNode *Node);
// IsPolygonContained возвращает TRUE если
// ограничивающий прямоугольник полигона пересекается с
// указанной кубической областью пространства
BOOL IsPolygonContained(
sPolygon *Polygon,
float XPos, float YPos, float ZPos,
float Size);
// CountPolygons возвращает количество полигонов
// в трехмерном кубе
unsigned long CountPolygons(
float XPos, float YPos, float ZPos,
float Size);
public:
cNodeTreeMesh(); // Конструктор
~cNodeTreeMesh(); // Деструктор
// Функции для создания и освобождения разделенной
// на узлы дерева сетки из исходного объекта cMesh с указанием
// максимального количества полигонов в области, которая больше
// заданного размера (вызывающего разделение узла)
BOOL Create(cGraphics *Graphics, cMesh *Mesh,
int TreeType = OCTREE,
float MaxSize = 256.0f, long MaxPolygons = 32);
BOOL Free();
// Визуализация объекта с использованием текущего преобразования
// вида и перегруженной дистанции видимости. Также можно указать
// для использования ранее вычисленную пирамиду видимого пространства,
// или функция сама вычислит собственную пирамиду
BOOL Render(cFrustum *Frustum=NULL, float ZDistance=0.0f);
// Получение ближайшей высоты выше или ниже точки
float GetClosestHeight(float XPos, float YPos, float ZPos);
// Получение высоты выше и ниже точки
float GetHeightBelow(float XPos, float YPos, float ZPos);
float GetHeightAbove(float XPos, float YPos, float ZPos);
// Проверяем, блокирует ли полигон путь от начала до конца
BOOL CheckIntersect(float XStart, float YStart,
float ZStart,
float XEnd, float YEnd,
float ZEnd,
float *Length);
};
Комментарии в приведенном выше классе достаточно хорошо описывают, что представляет каждая переменная и что делает каждая функция. В нескольких следующих разделах я опишу каждую функцию более подробно. Сейчас взгляните на таблицу 8.1, где перечислены и описаны все переменные cNodeTreeMesh.
Таблица 8.1. Переменные cNodeTreeMesh
| Переменная | Описание |
| m_Graphics | Указатель на ранее инициализированный объект cGraphics. |
| m_Frustum | Указатель на класс пирамиды видимого пространства cFrustum, который будет использоваться при операциях визуализации. |
| m_Timer | Текущий кадр (используется при визуализации для предотвращения перерисовок). |
| m_Size | Размер мира от центра (начала координат) до дальней грани по любой из трех осей (мир является кубом). |
| m_MaxSize | Максимальный размер узла, который может быть перед разделением (оно происходит, когда узел содержит слишком много полигонов). |
| m_ParentNode | Голова связанного списка узлов. |
| m_NumGroups | Количество групп материалов. |
| m_Groups | Массив групп материалов. |
| m_NumPolygons | Количество полигонов в исходной сетке. |
| m_MaxPolygons | Хранит максимальное количество полигонов, допустимое для узла (при его превышении происходит разделение узла). |
| m_PolygonList | Массив структур sPolygon, хранящих информацию о каждом полигоне сетки. |
| m_Mesh | Указатель на исходную сетку (структуру sMesh, используемую графическим ядром). |
| m_VertexPtr | Используется для доступа к буферу вершин исходной сетки. |
| m_VertexFVF | Дескриптор FVF исходной сетки. |
| m_VertexSize | Хранит размер одной вершины исходной сетки (в байтах). |
Продолжайте чтение главы, и я укажу, когда переменные класса вступают в игру, а сейчас пришло время больше узнать о функциях класса cNodeTreeMesh.
Функция cNodeTreeMesh::Create — это место где начинается весь процесс. Для создания структуры NodeTree вам необходима исходная сетка с которой мы будем работать, и лучше всего взять ее из объекта cMesh. Объект cMesh хранит список сеток, содержащихся в одном X-файле, и мы для простоты будем иметь дело только с первой сеткой из списка.
Передав функции Create указатель на инициализированный объект cGraphics, предварительно загруженный объект cMesh и тип дерева, который вы хотите использовать (QUADTREE или OCTREE), вы инициализируете класс, после чего он готов к визуализации.
Помимо уже упомянутых аргументов вам надо задать максимальное количество полигонов для узла и максимальный размер узла, прежде чем ему потребуется разделение (когда он содержит максимально возможное для узла количество полигонов).
BOOL cNodeTreeMesh::Create(cGraphics *Graphics, cMesh *Mesh,
int TreeType,
float MaxSize, long MaxPolygons)
{
ID3DXMesh *LoadMesh;
unsigned short *IndexPtr;
unsigned long *Attributes;
float MaxX, MaxY, MaxZ;
unsigned long i;
// Освобождаем предыдущую сетку
Free();
// Проверка ошибок
if((m_Graphics = Graphics) == NULL)
return FALSE;
if(Mesh == NULL)
return FALSE;
if(!Mesh->GetParentMesh()->m_NumMaterials)
return FALSE;
// Получаем сведения о сетке
m_Mesh = Mesh->GetParentMesh();
LoadMesh = m_Mesh->m_Mesh;
m_VertexFVF = LoadMesh->GetFVF();
m_VertexSize = D3DXGetFVFVertexSize(m_VertexFVF);
m_NumPolygons = LoadMesh->GetNumFaces();
m_MaxPolygons = MaxPolygons;
// Создаем список полигонов и групп
m_Polygons = new sPolygon[m_NumPolygons]();
m_NumGroups = m_Mesh->m_NumMaterials;
m_Groups = new sGroup[m_NumGroups]();
// Блокируем буфер индексов и буфер атрибутов
LoadMesh->LockIndexBuffer(D3DLOCK_READONLY,(void**)&IndexPtr);
LoadMesh->LockAttributeBuffer(D3DLOCK_READONLY, &Attributes);
Здесь мы видим кое-что новое. ID3DXMesh использует буфер вершин; кроме того, ID3DXMesh использует буфер индексов! Вы только что читали об этом в предыдущем разделе; D3DX использует буферы вершин и индексов для экономии памяти и ускорения визуализации, поскольку буфер индексов позволяет во время визуализации несколько раз использовать одну и ту же вершину без необходимости несколько раз сохранять координаты вершины в буфере вершин.
Также у объекта ID3DXMesh есть нечто, называемое буфер атрибутов (attribute buffer), представляющий собой массив значений, определяющих какой материал какой полигон использует. Между элементами массива и полигонами существует отношение один к одному. Именно этот буфер атрибутов используется, чтобы включать полигоны в соответствующие им группы материалов.
В последующем коде начинается перебор всех полигонов сетки с извлечением трех вершин, используемых для конструирования каждого полигона. Помимо этого, вы в структуре данных полигона сохраняете материал, применяемый для рисования этого полигона.
// Загрузка данных полигонов в структуры
for(i = 0; i < m_NumPolygons; i++) {
m_Polygons[i].Vertex0 = *IndexPtr++;
m_Polygons[i].Vertex1 = *IndexPtr++;
m_Polygons[i].Vertex2 = *IndexPtr++;
m_Polygons[i].Group = Attributes[i];
m_Polygons[i].Timer = 0;
m_Groups[Attributes[i]].NumPolygons++;
}
// Разблокирование буферов
LoadMesh->UnlockAttributeBuffer();
LoadMesh->UnlockIndexBuffer();
// Построение индексных буферов групп вершин
for(i = 0; i < m_NumGroups; i++) {
if(m_Groups[i].NumPolygons != 0)
m_Graphics->GetDeviceCOM()->CreateIndexBuffer(
m_Groups[i].NumPolygons * 3 * sizeof(unsigned short),
D3DUSAGE_WRITEONLY, D3DFMT_INDEX16, D3DPOOL_MANAGED,
&m_Groups[i].IndexBuffer, NULL);
}
В показанном выше коде массив индексов и буфер атрибутов сетки заблокированы. После этого вы просто строите список данных полигонов (какие вершины образуют полигон и какая группа материалов используется). Завершив построение списка данных полигонов, вы разблокируете буферы индексов и атрибутов и формируете фактические группы материалов.
Каждая группа материалов содержит объект IDirectIndexBuffer9 для хранения индексов вершин, которые надо рисовать. Чтобы создать этот буфер индексов вы используете функцию CreateIndexBuffer, во многом похожую на функцию CreateVertexBuffer, о которой вы читали в главе 2. Единственное различие в том, что буфер индексов использует для значений индексов переменные типа short (2 байта), и выделяет по три индекса на полигон. Обратите внимание, что нужно выделить достаточно индексов для каждого полигона, относящегося к каждой группе материалов.
// Получаем размер ограничивающего куба
MaxX = (float)max(fabs(Mesh->GetParentMesh()->m_Min.x),
fabs(Mesh->GetParentMesh()->m_Max.x));
MaxY = (float)max(fabs(Mesh->GetParentMesh()->m_Min.y),
fabs(Mesh->GetParentMesh()->m_Max.y));
MaxZ = (float)max(fabs(Mesh->GetParentMesh()->m_Min.z),
fabs(Mesh->GetParentMesh()->m_Max.z));
m_Size = max(MaxX, max(MaxY, MaxZ)) * 2.0f;
m_MaxSize = MaxSize;
// Создаем родительский узел
m_ParentNode = new sNode();
Здесь вычисляется точка наиболее удаленная от центра исходной сетки. Для упрощения вычислений мир считается идеальным кубом, поэтому мы используем расстояние от центра сетки до внешнего края в качестве размера мирового ограничивающего параллелепипеда. После создания родительского узла (m_ParentNode) вы блокируете буфер вершин сетки чтобы прочитать координаты вершин. И, наконец, узлы сортируются путем вызова функции SortNode.
// Сортировка полигонов в узлах
LoadMesh->LockVertexBuffer(D3DLOCK_READONLY,
(void**)&m_VertexPtr);
SortNode(m_ParentNode, 0.0f, 0.0f, 0.0f, m_Size);
LoadMesh->UnlockVertexBuffer();
m_Timer = 0; // Сброс таймера
return TRUE;
}
После сортировки буфер вершин сетки разблокируется и функция возвращает TRUE, сообщая об успешном завершении. Теперь представление сетки в виде узлов дерева готово к использованию. Завершив работу с этим представлением вы вызываете cNodeTreeMesh::Free для освобождения ресурсов сетки:
BOOL cNodeTreeMesh::Free()
{
delete m_ParentNode; // Удаляем родительский и дочерние узлы
m_ParentNode = NULL;
m_NumPolygons = 0; // Больше нет полигонов
delete [] m_PolygonList; // Удаляем массив полигонов
m_PolygonList = NULL;
m_NumGroups = 0; // Больше нет групп материалов
delete [] m_Groups; // Удаляем группы материалов
m_Groups = NULL;
m_Graphics = NULL;
return TRUE;
}
cNodeTreeMesh::SortNode — это рекурсивная функция (вызывающая сама себя), которая подсчитывает количество полигонов, находящихся в узле трехмерного пространства и решает надо ли разделить узел на четыре или восемь дочерних узлов (в зависимости от типа дерева). После того, как узлы соответствующим образом разделены, функция SortNode строит список полигонов, находящихся в узле трехмерного пространства.
Код функции SortNode начинается с проверки правильности переданных ей аргументов. Затем функция сохраняет координаты узла и начинает разделение узлов.
void cNodeTreeMesh::SortNode(sNode *Node,
float XPos, float YPos, float ZPos,
float Size)
{
unsigned long i, Num;
float XOff, YOff, ZOff;
// Проверка ошибок
if(Node == NULL)
return;
// Сохраняем координаты и размер узла
Node->XPos = XPos;
Node->YPos = (m_TreeType==QUADTREE)?0.0f:YPos;
Node->ZPos = ZPos;
Node->Size = Size;
// Смотрим, есть ли полигоны в узле
if(!(Num = CountPolygons(XPos, YPos, ZPos, Size)))
return;
// Разделяем узел, если его размер больше максимума
// и в нем слишком много полигонов
if(Size > m_MaxSize && Num > m_MaxPolygons) {
for(i = 0; i < (unsigned long)((m_TreeType==QUADTREE)?4:8); i++) {
XOff = (((i % 2) < 1) ? -1.0f : 1.0f) * (Size / 4.0f);
ZOff = (((i % 4) < 2) ? -1.0f : 1.0f) * (Size / 4.0f);
YOff = (((i % 8) < 4) ? -1.0f : 1.0f) * (Size / 4.0f);
// Смотрим, есть ли полигоны в ограничивающем
// параллелепипеде нового узла
if(CountPolygons(XPos + XOff, YPos + YOff, ZPos + ZOff,
Size/2.0f)) {
// Создаем новый дочерний узел
Node->Nodes[i] = new sNode();
// Сортируем полигоны с новым дочерним узлом
SortNode(Node->Nodes[i], XPos+XOff, YPos+YOff,
ZPos+ZOff, Size/2.0f);
}
}
return;
}
К этому моменту все полигоны, находящиеся в ограничивающем параллелепипеде узла посчитаны. Если полигонов слишком много и размер ограничивающего параллелепипеда узла достаточно большой, узел разделяется. Полученные в результате разделения узлы проходят тот же самый процесс. В процессе пустые узлы исключаются из последующей обработки, а узлы с полигонами отправляются назад функции SortNode (это и есть рекурсия).
// Выделяем место для списка указателей на полигоны
Node->NumPolygons = Num;
Node->PolygonList = new unsigned long[Num];
// Сканируем список полигонов, сохраняя указатели и назначая их
Num = 0;
for(i = 0; i < m_NumPolygons; i++) {
// Добавляем полигон к списку, если он находится
// в заданной области пространства
if(IsPolygonContained(&m_PolygonList[i],
XPos, YPos, ZPos, Size) == TRUE)
Node->PolygonList[Num++] = i;
}
}
Последний фрагмент кода SortNode выделяет массив индексов, указывающих на массив m_Polygons. Поскольку массив m_Polygons содержит данные всех полигонов, имеет смысл сократить объем используемой памяти, сохраняя в массиве PolygonList индекс элемента массива m_Polygons. (Индекс 0 в PolygonList указывает на данные полигона в m_Polygons[0], индекс 1 в PolygonList указывает на данные полигона в m_Polygons[1] и т.д.)
Когда приходит время визуализации, этот массив указателей используется для получения информации о каждом полигоне, включая индексы вершин и используемую группу материалов. Рисуемые полигоны позднее добавляются к буферу индексов соответствующей группы материалов с помощью функции AddNode.
Этот дуэт функций вы используете для того, чтобы определить, находится ли полигон в области трехмерного пространства, заданной ограничивающим параллелепипедом, и подсчитать общее количество полигонов, находящихся в заданной области.
BOOL cNodeTreeMesh::IsPolygonContained(sPolygon *Polygon,
float XPos, float YPos, float ZPos,
float Size)
{
float XMin, XMax, YMin, YMax, ZMin, ZMax;
sVertex *Vertex[3];
// Получаем вершины полигона
Vertex[0] = (sVertex*)&m_VertexPtr[m_VertexSize *
Polygon->Vertex[0]];
Vertex[1] = (sVertex*)&m_VertexPtr[m_VertexSize *
Polygon->Vertex[1]];
Vertex[2] = (sVertex*)&m_VertexPtr[m_VertexSize *
Polygon->Vertex[2]];
// Проверяем ось X заданной области пространства
XMin = min(Vertex[0]->x, min(Vertex[1]->x, Vertex[2]->x));
XMax = max(Vertex[0]->x, max(Vertex[1]->x, Vertex[2]->x));
if(XMax < (XPos - Size / 2.0f))
return FALSE;
if(XMin > (XPos + Size / 2.0f))
return FALSE;
В показанном выше коде (а также и в показанном ниже) определяется вершина, наиболее удаленная по оси X. Если полигон слишком далеко сдвинут влево или вправо от проверяемого ограничивающего параллелепипеда, то функция возвращает FALSE. То же самое выполняется и для двух других осей.
// Проверяем ось Y заданной области пространства (для октодерева)
if(m_TreeType == OCTREE) {
YMin = min(Vertex[0]->y, min(Vertex[1]->y, Vertex[2]->y));
YMax = max(Vertex[0]->y, max(Vertex[1]->y, Vertex[2]->y));
if(YMax < (YPos - Size / 2.0f))
return FALSE;
if(YMin > (YPos + Size / 2.0f))
return FALSE;
}
// Проверяем ось Z заданной области пространства
ZMin = min(Vertex[0]->z, min(Vertex[1]->z, Vertex[2]->z));
ZMax = max(Vertex[0]->z, max(Vertex[1]->z, Vertex[2]->z));
if(ZMax < (ZPos - Size / 2.0f))
return FALSE;
if(ZMin > (ZPos + Size / 2.0f))
return FALSE;
return TRUE;
}
unsigned long cNodeTreeMesh::CountPolygons(
float XPos, float YPos, float ZPos, float Size)
{
unsigned long i, Num;
// Возвращаемся, если нет полигонов для обработки
if(!m_NumPolygons)
return 0;
// Перебираем каждый полигон и считаем те,
// которые находятся в заданной области пространства
Num = 0;
for(i = 0; i < m_NumPolygons; i++) {
if(IsPolygonContained(&m_PolygonList[i], XPos, YPos, ZPos,
Size) == TRUE)
Num++;
}
return Num;
}
Как видите, CountPolygons в цикле перебирает все полигоны сетки и проверяет, находятся ли они внутри ограничивающего куба. Попавшие в заданное пространство полигоны подсчитываются и финальное значение счетчика возвращается вам. Функция используется чтобы определить сколько полигонов находится внутри узла при разделении и сортировке узлов.
Вы используете функцию cNodeTreeMesh::AddNode совместно с функцией Render. AddNode выполняет проверку видимого пространства для всех узлов и рекурсивно проверяет их дочерние узлы. При первом вызове функции AddNode ей передается переменная m_ParentNode для начала процесса с корневого узла.
void cNodeTreeMesh::AddNode(sNode *Node)
{
unsigned long i, Group;
sPolygon *Polygon;
short Num;
if(Node == NULL)
return;
// Проверка пирамиды видимого пространства
// в зависимости от типа дерева
BOOL CompletelyContained = FALSE;
if(m_TreeType == QUADTREE) {
if(m_Frustum->CheckRectangle(
Node->XPos, 0.0f, Node->ZPos,
Node->Size/2.0f, m_Size/2.0f,
Node->Size / 2.0f,
&CompletelyContained) == FALSE)
return;
} else {
if(m_Frustum->CheckRectangle(
Node->XPos, Node->YPos, Node->ZPos,
Node->Size/2.0f, Node->Size/2.0f,
Node->Size/2.0f,
&CompletelyContained) == FALSE)
return;
}
И снова вы видите проверку пирамиды видимого пространства, которую я упоминал ранее. Здесь режимы квадродерева и октодерева различаются. Для квадродерева, являющегося двухмерной структурой, проверяются только два измерения (Y для двухмерного представления всегда отбрасывается). В случае октодерева узел может находиться в любом месте трехмерного пространства, поэтому как минимум одна точка должна быть видима.
Теперь функция AddNode решает, должны ли быть добавлены дочерние узлы (в том случае, если они содержат полигоны). Добавление узлов заканчивается, когда у текущего узла нет потомков. В этом случае обрабатывается следующий родительский узел и так до тех пор, пока не будут обработаны все узлы. (Обратите внимание, что если узел полностью находится внутри пирамиды видимого пространства, проверять его дочерние узлы не надо.)
if(CompletelyContained == FALSE) {
// Сканируем другие узлы
Num = 0;
for(i = 0; i < (unsigned long)((m_TreeType==QUADTREE)?4:8); i++) {
if(Node->Nodes[i] != NULL) {
Num++;
AddNode(Node->Nodes[i]);
}
}
// Не надо продолжать, если есть другие узлы
if(Num)
return;
}
Теперь функция AddNode проверяет, содержит ли рассматриваемый узел какие-нибудь полигоны. Если в узле есть полигоны, каждый из них проверяется видим ли он (полигоны у которых альфа-значение материала равно 0.0, считаются невидимыми).
AddNode добавляет видимые полигоны в буфер индексов соответствующей группы материалов и сохраняет количество рисуемых в узле полигонов. В каждом кадре количество полигонов, визуализируемых в каждой группе материалов, сбрасывается функцией Render. Следующий код увеличивает количество рисуемых полигонов:
// Добавляем содержащиеся полигоны (если есть)
if(Node->NumPolygons != 0) {
for(i = 0; i < Node->NumPolygons; i++) {
// Получаем указатель на полигон
Polygon = &m_Polygons[Node->PolygonList[i]];
// Рисуем, только если уже
// не был нарисован в этом кадре
if(Polygon->Timer != m_Timer) {
// Отмечаем полигон как обработанный в этом кадре
Polygon->Timer = m_Timer;
// Получаем группу материалов полигона
Group = Polygon->Group;
// Проверяем правильность указания группы
// и что материал непрозрачный
if(Group < m_NumGroups &&
m_Mesh->m_Materials[Group].Diffuse.a != 0.0f) {
// Копируем индексы в буфер индексов
*m_Groups[Group].IndexPtr++ = Polygon->Vertex0;
*m_Groups[Group].IndexPtr++ = Polygon->Vertex1;
*m_Groups[Group].IndexPtr++ = Polygon->Vertex2;
// Увеличиваем счетчик рисуемых полигонов в группе
m_Groups[Group].NumPolygonsToDraw++;
}
}
}
}
}
После завершения функции AddNode вы получаете полный набор буферов индексов групп материалов, готовый к визуализации.
Вы дошли до конца класса cNodeTreeMesh, и разве может быть лучшее место для размещения функции, вознаграждающей вас визуализацией полигонов? Функции cNodeTreeMesh::Render можно передать необязательную пирамиду видимого пространства, которая будет использоваться вместо внутренней пирамиды видимого пространства.
Кроме того, поскольку функция визуализации в работе использует пирамиду видимого пространства, необходим способ переопределять глубину поля зрения. Это поможет, если вы захотите рисовать только те полигоны сетки, которые находятся не далее указанного расстояния от точки просмотра. Например, если протяженность пирамиды видимого пространства составляет 20 000 единиц, а вы хотите визуализировать только полигоны, находящиеся в пределах 5 000 единиц, задайте 5 000 для ZDistance.
Функция Render начинается с вычисления пирамиды видимого пространства и блокировки буфера вершин:
BOOL cNodeTreeMesh::Render(cFrustum *Frustum, float ZDistance)
{
D3DXMATRIX Matrix; // Матрица, используемая для вычислений
cFrustum ViewFrustum; // Локальная пирамида видимого пространства
IDirect3DVertexBuffer9 *pVB = NULL;
unsigned long i;
// Проверка ошибок
if(m_Graphics==NULL || m_ParentNode==NULL || !m_NumPolygons)
return FALSE;
// Конструируем пирамиду видимого пространства
// (если она не передана в параметре)
if((m_Frustum = Frustum) == NULL) {
ViewFrustum.Construct(m_Graphics, ZDistance);
m_Frustum = &ViewFrustum;
}
// Делаем матрицу мирового преобразования единичной,
// чтобы сетка уровня визуализировалась вокруг начала координат
// как была разработана
D3DXMatrixIdentity(&Matrix);
m_Graphics->GetDeviceCOM()->SetTransform(D3DTS_WORLD,&Matrix);
// Блокируем буфер индексов группы
for(i = 0; i < m_NumGroups; i++) {
if(m_Groups[i].NumPolygons) {
m_Groups[i].IndexBuffer->Lock(
0, m_Groups[i].NumPolygons * 3 * sizeof(unsigned short),
(void**)&m_Groups[i].IndexPtr, 0);
}
m_Groups[i].NumPolygonsToDraw = 0;
}
Сейчас буферы индексов групп материалов заблокированы и готовы принимать информацию об индексах от функции AddNode. В каждой группе материалов обнуляется количество рисуемых полигонов, и в следующих строках кода все видимые полигоны (через узлы) будут добавлены к буферам индексов групп материалов.
Теперь увеличивается значение переменной m_Timer (чтобы увеличить счетчик кадров и гарантировать, что полигоны не будут рисоваться по несколько раз в одном и том же кадре) и вызывается функция AddNode для родительского узла.
// Увеличиваем счетчик кадров
m_Timer++;
// Добавляем рисуемые полигоны в списки групп
AddNode(m_ParentNode);
Вы готовы визуализировать видимые полигоны. Для этого вам необходим доступ к буферу вершин исходной сетки; здесь придет на помощь вызов ID3DXMesh::GetVertexBuffer. Затем вы устанавливаете соответствующий потоковый источник данных, шейдер FVF, и в цикле перебираете каждую группу материалов, устанавливая каждый материал и текстуру и визуализируя полигоны с помощью вызова IDirect3DDevice9::DrawIndexedPrimitive. Разблокируйте буфер вершин сетки и сделайте все необходимое!
// Получаем указатель на буфер вершин
m_Mesh->m_Mesh->GetVertexBuffer(&pVB);
// Устанавливаем вершинный шейдер и источник данных
m_Graphics->GetDeviceCOM()->SetStreamSource(0, pVB, 0, m_VertexSize);
m_Graphics->GetDeviceCOM()->SetFVF(m_VertexFVF);
// Разблокируем буфер вершин и рисуем
for(i = 0; i < m_NumGroups; i++) {
if(m_Groups[i].NumPolygons)
m_Groups[i].IndexBuffer->Unlock();
if(m_Groups[i].NumPolygonsToDraw) {
m_Graphics->GetDeviceCOM()->SetMaterial(&m_Mesh->m_Materials[i]);
m_Graphics->GetDeviceCOM()->SetTexture(0, m_Mesh->m_Textures[i]);
m_Graphics->GetDeviceCOM()->SetIndices(m_Groups[i].IndexBuffer);
m_Graphics->GetDeviceCOM()->DrawIndexedPrimitive(
D3DPT_TRIANGLELIST, 0, 0,
m_Mesh->m_Mesh->GetNumVertices(), 0,
m_Groups[i].NumPolygonsToDraw);
}
}
// Освобождаем буфер вершин
if(pVB != NULL)
pVB->Release();
return TRUE;
}
Вы можете недоумевать, как в целом работает эта схема визуализации с буфером индексов. В Direct3D вы должны указать, какой буфер индексов и какой буфер вершин используются для визуализации. Это делается с помощью функций SetIndicies и SetStreamSource.
Когда выполняется сама визуализация, вы, вместо вызова функции DrawPrimitive, о которой читали в главе 2, обращаетесь к функции DrawIndexedPrimitive. Эта функция использует предоставленные вами буферы вершин и индексов для рисования полигонов заданного типа (списков треугольников, полос, вееров и т.д.). Параметры DrawIndexedPrimitive те же самые, что у DrawPrimitive, так что здесь проблем возникнуть не должно.
Если в своем проекте вы используете графическое ядро, для применения класса cNodeTreeMesh достаточно включить его в проект, предоставить исходную сетку, с которой он будет работать и визуализировать ее! С другой стороны, если вы не хотите использовать графическое ядро, потребуется некоторая переработка. В приведенном ниже коде вы увидите фрагменты, где используются классы графического ядра (я постарался свести их число к минимуму), и сейчас у вас достаточно знаний, чтобы приспособить движок NodeTree к вашему собственному графическому ядру.
Демонстрационная программа NodeTree есть на прилагаемом к книге CD-ROM. Вы найдете ее в каталоге BookCode\Chap08\NodeTree. А сейчас взгляните на код, показывающий как быстро построить дерево узлов и визуализировать сетку:
// Graphics = ранее инициализированный объект cGraphics
cMesh Mesh;
cNodeTreeMesh NodeTreeMesh;
cCamera Camera;
cFrustum Frustum;
// Загружаем сетку с диска
Mesh.Load(&Graphics, "mesh.x");
NodeTreeMesh.Create(&Graphics, &Mesh, OCTREE);
// Устанавливаем позицию камеры и
// создаем пирамиду видимого пространства
Camera.Point(0.0f, 100.0f, -200.0f, 0.0f, 0.0f, 0.0f);
Graphics.SetCamera(&Camera);
Frustum.Construct(&Graphics);
// Начинаем сцену, визуализируем сетку,
// завершаем сцену и отображаем ее
// Визуализируем все
Graphics.Clear(D3DCOLOR_RGBA(0,0,0,0));
if(Graphics.BeginScene() == TRUE) {
NodeTreeMesh.Render(&Frustum);
Graphics.EndScene();
}
Graphics.Display();
// Освобождаем все
NodeTreeMesh.Free();
Mesh.Free();
| netlib.narod.ru | < Назад | Оглавление | Далее > |