| < Назад Далее > |
В предыдущих статьях вскользь упоминался стек. Рассмотрим это понятие более подробно.
Стеком называют область программы для временного хранения произвольных данных. Отличительной особенностью стека является своеобразный порядок выборки содержащихся в нем данных: в любой момент времени в стеке доступен только верхний элемент, т.е. элемент, загруженный в стек последним. Выгрузка из стека верхнего элемента делает доступным следующий элемент.
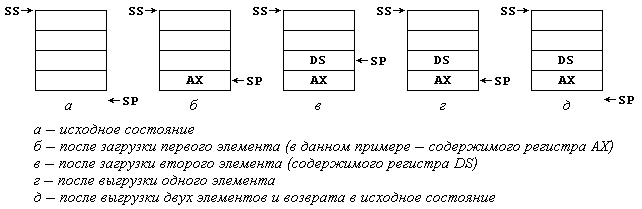
Элементы стека располагаются в области памяти, отведенной под стек, начиная со дна стека (т.е. с его максимального адреса) по последовательно уменьшающимся адресам. Адрес верхнего, доступного элемента хранится в регистре указателя стека SP. Как и любая другая область памяти программы, стек должен входить в какой-то сегмент или образовывать отдельный сегмент. В любом случае сегментный адрес этого сегмента помещается в сегментный регистр стека SS. Таким образом, пара регистров SS:SP описывают адрес доступной ячейки стека: в SS хранится сегментный адрес стека, а в SP — относительный адрес доступной (текущей) ячейки (рис. 6.1а). Обратите внимание на то, что в исходном состоянии указатель стека SP указывает на ячейку, лежащую под дном стека и не входящую в него.
Рис. 6.1. Организация стека
Загрузка в стек осуществляется специальной командой работы со стеком push (протолкнуть). Эта команда сначала уменьшает на 2 содержимое указателя стека, а затем помешает операнд по адресу, находящемуся в SP. Если, например, мы хотим временно сохранить в стеке содержимое регистра АХ, следует выполнить команду
push АХ
Стек переходит в состояние, показанное на рис. 6.1б. Видно, что указатель стека смещается на два байта вверх и по этому адресу записывается указанный в команде проталкивания операнд. Следующая команда загрузки в стек, например,
push DS
переведет стек в состояние, показанное на рис. 6.1в. В стеке будут теперь храниться два элемента, причем доступным будет только верхний, на который указывает указатель стека SP. Если спустя какое-то время нам понадобилось восстановить исходное содержимое сохраненных в стеке регистров, мы должны выполнить команды выгрузки из стека pop (вытолкнуть):
pop DS
pop AX
Состояние стека после выполнения первой команды показано на рис. 6.1г, а после второй — на рис. 6.1д. Для правильного восстановления содержимого регистров выгрузка из стека должна выполняться в порядке, строго противоположном загрузке — сначала выгружается элемент, загруженный последним, затем предыдущий элемент и т.д.
Обратите внимание на то, что после выгрузки сохраненных в стеке данных они физически не стерлись, а остались в области стека на своих местах. Правда, при «стандартной» работе со стеком они оказываются недоступными. Действительно, поскольку указатель стека SP указывает под дно стека, стек считается пустым; очередная команда push поместит новые данные на место сохраненного ранее содержимого АХ, затерев его. Однако пока стек физически не затерт, сохраненными и уже выбранными из него данными можно пользоваться, если помнить, в каком порядке они расположены в стеке. Этот прием часто используется при работе с подпрограммами и в дальнейшем будет описан подробнее.
В примерах 1.1 и 5.1 мы не заботились о стеке, поскольку, на первый взгляд, нашей программе стек был не нужен. Однако на самом деле это не так. Стек автоматически используется системой в ряде случаев, в частности, при переходе на подпрограммы и при выполнении команд прерывания int. И в том. и в другом случае процессор заносит в стек адрес возврата, чтобы после завершения выполнения подпрограммы или программы обработки прерывания можно было вернуться в ту точку вызывающей программы, откуда произошел переход. Поскольку в нашей программе есть две команды int 21h, операционная система при выполнении программы дважды обращалась к стеку. Где же был стек программы, если мы его явным образом не создали? Чтобы разобраться в этом вопросе, изменим пример 5.1, введя в него строки работы со стеком.
Пример 6.1. Программа, работающая со стеком
text segment 'code' ; (1) Начало сегмента команд
assume CS:text, DS:data ; (2) CS -> команды, DS -> данные
begin: mov AX,text ; (3) Адрес сегмента данных загрузим
mov DS,AX ; (4) сначала в AX, затем в DS
push DS ; (5) Загрузим в стек содержимое DS
pop ES ; (6) Выгрузим его из стека в ES
mov AH,9 ; (7) Функция DOS вывода на экран
mov DX,offset message ; (8) Адрес выводимого сообщения
int 21h ; (9) Вызов DOS
mov AX,4C00h ; (10) Функция завершения программы
int 21h ; (11) Вызов DOS
text ends ; (12) Конец сегмента команд
data segment ; (13) Начало сегмента данных
message db 'Наука имеет много гитик$' ; (14) Выводимый текст
data ends ; (15) Конец сегмента данных
end begin ; (16) Конец программы с точкой входа
В предложении 5 содержимое DS сохраняется в стеке, а в следующем предложении выгружается из стека в ES. После этой операции оба сегментных регистра, и DS. и ES, будут указывать на один и тот же сегмент данных. В нашей программе эти строки не имеют практического смысла, но вообще здесь продемонстрирован удобный прием переноса содержимого одного сегментного регистра в другой. Выше уже отмечаюсь, что в силу особенностей архитектуры микропроцессора для сегментных регистров действуют некоторые ограничения. Так, в сегментный регистр нельзя непосредственно загрузить адрес сегмента; нельзя также перенести число из одного сегментного регистра в другой. При необходимости выполнить последнюю операцию в качестве «перевалочного пункта» стек.
Запустите под управлением отладчика программу 6.1. Посмотрите, чему равно содержимое регистров SS и SP. Вы увидите, что в SS находится тот же адрес памяти, что и в CS; отсюда можно сделать вывод, что сегменты команд и стека совпадают. Однако содержимое SP равно 0. Первая же команда push уменьшит содержимое SP на 2, т.е. поместит в SP –2. Значит ли это, что стек будет расти, как ему и положено, вверх, но не внутри сегмента команд, а над ним, по адресам –2, –4, –6 и т.д. относительно верхней границы сегмента команд? Оказывается, это не так.
Если взять 16-разрядный двоичный счетчик, в котором записан 0, и послать в него два вычитающих импульса, то после первого импульса в нем окажется число FFFFh, а после второго — FFFEh. При желании мы можем рассматривать число FFFEh, как –2 (что и имеет место при работе со знаковыми числами, о которых будет идти речь позже), однако процессор при вычислении адресов рассматривает содержимое регистров, как целые числа без знака, и число FFFEh оказывается эквивалентным не –2, а 65534. В результате первая же команда занесения данного в стек поместит это данное не над сегментом команд, а в самый его конец, в последнее слово по адресу CS:FFFEh. При дальнейшем использовании стека его указатель будет смешаться в сторону меньших адресов, проходя значения FFFCh, FFFAh и т.д.
Таким образом, если в программе отсутствует явное объявление стека, система сама создает стек по умолчанию в конце сегмента команд.
Рассмотренное явление, когда при уменьшении адреса после адреса 0 у нас получился адрес FFFFh, т.е. от начала сегмента мы прыгнули сразу в его конец, носит название циклического возврата или оборачивания адреса. С этим явлением приходится сталкиваться довольно часто.
Расположение стека в конце сегмента команд не приводит к каким-либо неприятностям, пока размер программы далек от граничной величины 64 К. В этом случае начало сегмента команд занимают коды команд, а конец — стек. Если, однако, размер программы приближается к 64 К, то для стека остается все меньше места. При интенсивном использовании стека в программе может получиться, что по мере занесения в стек новых данных, стек дорастет до последних команд сегмента команд и начнет затирать эти команды. Очевидно, что этого нельзя допускать. В то же время система не проверяет, что происходит со стеком и никак не реагирует на затирание команд или данных. Таким образом, оценка размеров собственно программы, данных и стека является важным этапом разработки программы.
Современные программы часто имеют значительный размер (даже не помещаясь в один сегмент команд), а стек иногда используется для хранения больших по объему массивов данных. Поэтому целесообразно ввести в программу отдельный сегмент стека, определив его размер, исходя из требований конкретной программы. Это и сделано в следующем примере.
Выполняя программу 6.1 по шагам, пронаблюдайте, как команды push и pop изменяют содержимое регистров SP и ES. Выведите на экран дамп памяти начиная с адреса SS:FFF0h. Убедитесь, что содержимое DS действительно записалось в память по адресу SS:FFFEh, и так и осталось там после извлечения содержимого стека и восстановления его указателя.
Что еще имеется в нашей двухсегментной программе, кроме сегментов команд и данных? При загрузке программы в память она будет выглядеть так, как это показано на рис. 6.2.
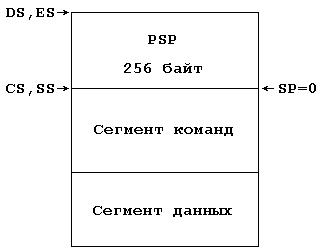
Рис. 6.2. Образ памяти программы EXE со стеком по умолчанию
Образ программы в памяти начинается с очень важной структуры данных, которую мы будем называть префиксом программы. В оригинальной литературе эта структура носит не очень удачное название Program Segment Prefics (или сокращенно PSP), т.е. «префикс программного сегмента». PSP образуется и заполняется системой в процессе загрузки программы в память; он всегда имеет размер 256 байт и содержит поля данных, используемые системой (а часто и самой программой) в процессе выполнения программы. К составу полей PSP мы еще не раз будем возвращаться в этой книге.
Вслед за PSP располагаются сегменты программы. Поскольку объявления сегментов сделаны нами наипростейшим образом (операторы segment не сопровождаются операндами-описателями), порядок размещения сегментов в памяти совпадает с порядком их объявления в программе, что упрощает исследование и отладку программы. Для большинства программ не имеет значения, в каком порядке вы будете объявлять сегменты, хотя встречаются программы, для которых порядок сегментов существен. Для таких программ предложения с операторами segment будут выглядеть сложнее.
В процессе загрузки программы в память сегментные регистры автоматически инициализируются следующим образом: ES и DS указывают на начало PSP (что дает возможность, сохранив их содержимое, обращаться затем в программе к PSP), CS — на начало сегмента команд. SS, как мы экспериментально убедились, также в нашем случае указывает на начало сегмента команд. Как мы увидим позже, верхняя половина PSP занята важной для системы и самой программы информацией, а нижняя половина (128 байт) практически свободна.
Поскольку после загрузки программы в память оба сегментных регистра данных указывают на PSP, сегмент данных программы оказывается не адресуемым. Не забывайте об этом! Если вы позабудете инициализировать регистр DS так, как это сделано в предложениях 3 и 4 нашей программы, вы не сможете обращаться к своим данным. При этом транслятор не выдаст никаких ошибок, но программа будет выполняться неправильно. Поставьте поучительный эксперимент: уберите из текста программы 6.1 строки инициализации регистра DS (проще всего не стирать эти строки, а поставить в их начале знак комментария — символ «;»). Оттранслируйте, скомпонуйте и выполните такой вариант программы. Ничего ужасного не произойдет, но на экран будет выведена какая-то ерунда. Возможно, в конце этой ерунды будет и строка «Наука умеет много гитик». Почему так получилось? Когда начинает выполняться функция DOS 09h, она предполагает, что полный двухсловный адрес выводимой на экран строки находится в регистрах DS:DX (в DS — сегментный адрес, в DX — относительный). У нас же сегментный регистр DS указывает на PSP. В результате на экран будет выводиться содержимое PSP, который заполнен адресами, кодами команд и другой числовой (а не символьной) информацией.
Рассмотрим теперь программу с тремя сегментами: команд, данных и стека. Такая структура широко используется для относительно несложных программ.
Пример 6.2. Программа с тремя сегментами
text segment 'code' ; (1) Начало сегмента команд
assume CS:text, DS:data ; (2) CS -> команды, DS -> данные
begin: mov AX,text ; (3) Адрес сегмента данных загрузим
mov DS,AX ; (4) сначала в AX, затем в DS
push DS ; (5) Загрузим в стек содержимое DS
pop ES ; (6) Выгрузим его из стека в ES
mov AH,9 ; (7) Функция DOS вывода на экран
mov DX,offset message ; (8) Адрес выводимого сообщения
int 21h ; (9) Вызов DOS
mov AX,4C00h ; (10) Функция завершения программы
int 21h ; (11) Вызов DOS
text ends ; (12) Конец сегмента команд
data segment ; (13) Начало сегмента данных
message db 'Наука имеет много гитик$' ; (14) Выводимый текст
data ends ; (15) Конец сегмента данных
stk segment stack ; (16) Начало сегмента стека
dw 128 dup (0) ; (17) Под стек отведено 128 слов
stk ends ; (18) Конец сегмента стека
end begin ; (19) Конец текста программы
В программе 6.2 вслед за сегментом данных объявлен еше один сегмент, которому мы дали имя stk. Так же, как и другие сегменты, сегмент стека можно назвать как угодно. Строка описания сегмента стека (предложение 16) должна содержать так называемый тип объединения — описатель stack. Тип объединения указывает компоновщику, каким образом должны объединяться одноименные сегменты разных программных модулей, и используется главным образом в тех случаях, когда отдельные части программы располагаются в разных исходных файлах (например, пишутся несколькими программистами) и объединяются на этапе компоновки. Хотя для одномодульных программ тип объединения обычно не имеет значения, для сегмента стека обязательно указание типа stack, поскольку в этом случае при загрузке программы выполняется автоматическая инициализация регистров SS (сегментным адресом стека) и SP (смешением его конца).
В приведенном примере для стека зарезервировано 128 слов памяти, что более чем достаточно для несложной программы.
Заметим, что получившаяся у нас программа является типичной и аналогичная структура будет использоваться в большинстве последующих примеров.
Подготовьте программу 6.2 к выполнению. Запустите ее под управлением отладчика CV, изучите расположение сегментов программы в памяти, обратив особое внимание на содержимое регистров SS и SP. Убедитесь, что в программе образовался отдельный сегмент стека размером 100h байт (128 слов = 256 байт). Поинтересуйтесь, где сохраняется значение DS при выполнении предложения 5.