| netlib.narod.ru | < Назад | Оглавление | Далее > |
Каждое слово-команда, известное форт-системе, хранится в оперативной памяти (в словаре) в виде специальной структуры данных — словарной статьи, состоящей из поля имени, поля связи, поля кода и поля параметров. Стандарт не фиксирует порядок взаимного расположения этих полей, оставляя его на усмотрение разработчиков реализации. Как правило, поля располагаются подряд в том порядке, как они перечислены выше.
Поля имени и связи вместе образуют заголовок словарной статьи, который нужен для поиска статьи по имени слова. Результатом поиска являются поля кода и параметров, которые вместе образуют собственно тело словарной статьи, определяющее действие, связанное с данным словом, т.е. его семантику. Согласно стандарту словарную статью представляет адрес ее поля кода, исходя из которого можно получить адреса всех других ее полей. Поскольку именно этот адрес компилируется в шитый код, то он также называется адресом компиляции.
Поле имени содержит имя слова в виде строки со счетчиком. Стандарт ограничивает максимальную длину имени 31 литерой (5 двоичными разрядами), чтобы остающиеся разряды в байте счетчика можно было использовать под специальные признаки. Важнейший из них — признак немедленного исполнения, который обычно занимает старший разряд байта-счетчика. Таким образом, поле имени имеет переменную длину, которая определяется значением счетчика.
Поле связи занимает 2 байта и содержит адрес заголовка предыдущей словарной статьи. Через это поле словарные статьи связаны в цепные списки, в которых можно вести поиск статьи по имени слова. Поле связи первой статьи в списке содержит некоторое специальное значение, обычно нуль. Новые слова добавляются в конец списка, и поиск слов ведется от конца списка к началу.
Тело словарной статьи реализуется через шитый код в одной из его разновидностей. Для определенности примем за основу косвенный шитый код. В этом случае интерпретатор шитого кода называется адресным интерпретатором форт-системы, поскольку интерпретирует последовательность адресов, каждый из которых является адресом компиляции некоторой словарной статьи (адресом ее поля кода). В качестве собственных данных адресный интерпретатор использует стек возвратов и указатель на текущее место в интерпретируемой последовательности адресов.
Поле кода словарной статьи в случае косвенного шитого кода занимает 2 байта и содержит адрес машинной программы, которая и выполняет действие, связанное с данным словом. Точка NEXT адресного интерпретатора обеспечивает этой программе доступ к полю параметров данной словарной статьи. Для статей, соответствующих определению через двоеточие, поле кода содержит адрес точки CALL адресного интерпретатора, а поле параметров представляет собой последовательность адресов словарных статей, входящих в данное определение. Завершается такая последовательность адресом словарной статьи EXIT (выход), который компилируется завершающей данное определение точкой с запятой. Для словарных статей нижнего уровня, т.е. реализованных непосредственно в машинном коде, поле кода содержит адрес соответствующей машинной программы, которая обычно располагается в поле параметров этой статьи. Таким образом, можно сказать, что поле кода словарной статьи содержит адрес машинной программы-интерпретатора поля параметров. Все слова, определенные через двоеточие, имеют в качестве интерпретатора действие CALL адресного интерпретатора, слова нижнего уровня наоборот имеют каждое свой отдельный интерпретатор в виде машинной программы, размещенной в поле параметров. В частности, такой программой для слова EXIT является действие RETURN адресного интерпретатора.
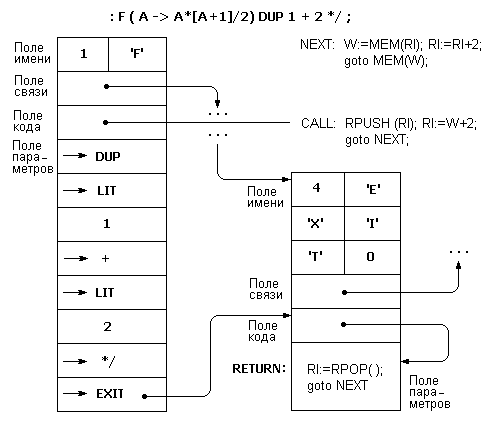
На рис. 2.4. приведены адресный интерпретатор и структура словарной статьи для определения
: F ( A ---> A*[A+1]/2 ) DUP 1+ 2 */ ;
вычисляющего сумму натуральных чисел от 1 до A по известной формуле. В качестве языка нижнего уровня для записи действий адресного интерпретатора применяется очевидная нотация. Переменная RI обозначает указатель текущего места в интерпретируемом коде, процедура MEM дает значение, находящееся по заданному адресу в памяти форт-системы. Процедуры RPUSH и RPOP используются для обращения к стеку возвратов с тем, чтобы положить значение на его вершину и снять верхнее значение.
Рис. 2.4. Адресный интерпретатор и структура словарной статьи для косвенного шитого кода
На рис. 2.4 изображены две словарные статьи: верхнего уровня для слова F, определенного через двоеточие, и нижнего уровня для слова EXIT, являющаяся к тому же частью адресного интерпретатора.
Поле имени каждой статьи начинается байтом-счетчиком, в котором записано число литер в имени слова. Далее располагаются коды самих этих литер.
Вслед за полем имени идет поле связи, содержащее адрес поля имени предыдущей словарной статьи. В тех реализациях, где двухбайтные значения должны располагаться с четного адреса, поле имени тоже располагают с четного адреса, дополняя его (как в случае слова EXIT) до четного числа байт специальным кодом (обычно пробелом или нулем).
Поле кода словарной статьи содержит адрес машинной программы. Для слова F это адрес точки CALL адресного интерпретатора, для слова EXIT — адрес его поля параметров, где и располагается соответствующая программа.
Наконец, в соответствии с техникой шитого кода в поле параметров статьи для слова F располагается последовательность адресов полей кода словарных статей тех слов, из которых составлено его определение. В этих адресах перед именем слова стоит знак ->. Скомпилированное число занимает две ячейки: в первой находится адрес специального служебного слова LIT (от LITERAL — литерал), а во второй — значение данного числа. Действие слова LIT состоит в том, что значение числа кладется на стек данных, а указатель интерпретации передвигается дальше, обходя это значение в шитом коде:
LIT: W:=MEM(RI); PUSH(W); RI:=RI+2; goto NEXT;
Здесь используется тот факт, что в момент перехода на очередную машинную программу в действие NEXT указатель текущего места RI уже установлен на следующий элемент интерпретируемой последовательности адресов.
Адреса полей словарной статьи имеют традиционные обозначения, которые представляют аббревиатуры их английских названий:
NFA - Name Field Address - адрес поля имени LFA - Link Field Address - адрес поля связи CFA - Code Field Address - адрес поля кода PFA - Parameter Field Address - адрес поля параметров
Представлением словарной статьи считается адрес ее поля кода. Стандартное слово >BODY (от body — тело) CFA --> PFA преобразует его в адрес поля параметров. По аналогии во многих реализациях введен следующий ряд слов для переходов между остальными полями статьи:
BODY> PFA ---> CFA >NAME CFA ---> NFA NAME> NFA ---> CFA N>LINK NFA ---> LFA L>NAME LFA ---> NFA
Их реализация определяется принятой структурой словарной статьи.
Стандарт предусматривает слово EXECUTE (исполнить) CFA -->, которое снимает со стека адрес поля кода словарной статьи и исполняет ее. Непосредственно под этим значением в стеке должны находиться параметры, необходимые данному слову. Такой механизм открывает широкие возможности для передачи слов-команд в качестве параметров.
| netlib.narod.ru | < Назад | Оглавление | Далее > |